梯度下降法 Gradient Descent Method
本章中我们开始利用梯度信息解决最优化问题。基本的梯度下降法采用迭代法,基于“梯度方向是函数上升最快的方向”,每一轮迭代向梯度的反方向走一步,即
其中
Vanilla Analysis
为了方便进行收敛性分析,我们假定目标函数
在实际计算时,我们往往难以找到精确解,因此对于优化目标
我们往往目标会改为找到接近最优解的一个解即可,即
一个自然的问题是,我们如何约束
方便起见,简写
利用
将前
由凸函数性质,有
将前
于是可得关于平均误差的上界
在这个简单的证明中,还存在几个问题
- 步长会对结果产生很大影响,不知道
等参数的情况下难以约束上界 - 不能保证最后一步就是最好的解
Lipschitz Convex Functions
要使上述上界可求,我们要对
其中对
那么可以利用基本不等式得到
不妨设 为
要使得误差降低到
于是得到收敛率
Smooth Convex Functions
Smoothness
对于处处可导的函数
则称
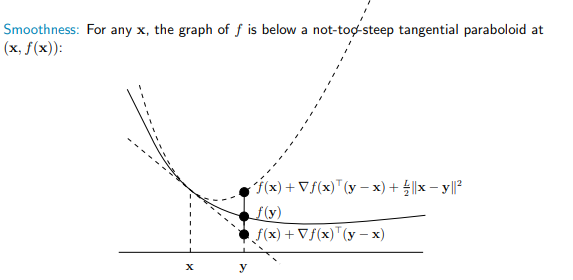
如图所示,Smoothness 是函数在切点处画出的二次曲线,作为函数的上界。
事实上,Smoothness 即在函数梯度上的 Lipschitz Continuity,即
在这里我们给出以上两个关系的等价性证明。
一方面,当梯度满足 Lipschitz Continuity 时,由于
利用 Lipschitz Continuity 性质,有
因此构造积分
于是 Smoothness 得证。
另一方面,当函数满足 Smoothness 时,有
交换
两式相加即可得到
于是梯度 Lipschitz Continuity 得证。
综上所述,函数 Smoothness 即为函数梯度 Lipschitz Continuity。
Convergence
考虑上一节中提出的 Smoothness,我们虽然不知道函数
最小化 Smoothness 上界,简写为 RHS,得到
即
可以证明,当
以下给出证明:
由于
代入
即
代回 Vanilla Analysis,有
移项得
由于迭代式每一步都是最小化上界,因此最后一步一定是最优的,即
要使得误差降低到
于是得到收敛率
Smooth and Strongly Convex Functions
Strongly Convex
对于处处可导的函数
则称
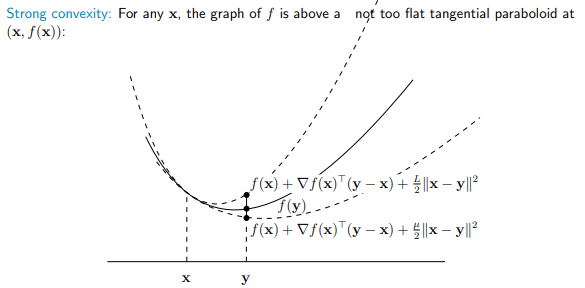
如图所示,Strongly Convex 是一个比 Convex 更强的下界。当一个函数既是 Strongly Convex 又是 Smooth 的时,直觉上这个函数的变化范围应该更小,因此收敛速度应该更快。
Convergence
假设我们的目标函数是
使用上一节所得的迭代式,即
可以证明,上述迭代式是收敛的,且收敛速度为
以下给出证明:
由 Vanilla Analysis 有
由 Strongly Convex 有
代入 Vanilla Analysis,有
整理得
考虑噪声项
因此有
连乘展开得
由 Smoothness 且
代入上式,有
要使得误差降低到
于是得到收敛率